
정리노트
Deep Learning (7) _Batch Normalization 본문
오늘 포스팅의 Reference : Stanford University CS231n: Deep Learning for Computer Vision
Stanford University CS231n: Deep Learning for Computer Vision
Course Description Computer Vision has become ubiquitous in our society, with applications in search, image understanding, apps, mapping, medicine, drones, and self-driving cars. Core to many of these applications are visual recognition tasks such as image
cs231n.stanford.edu
오늘 다뤄볼 'Batch Normalization'은 이와는 조금 다르게
레이어 중간중간 'Mini-Batch'단위로 Normalization을 진행해주는 기법을 말한다.
Normalizing your data (specifically, input and batch normalization). (jeremyjordan.me)
Normalizing your data (specifically, input and batch normalization).
In this post, I'll discuss considerations for normalizing your data - with a specific focus on neural networks. In order to understand the concepts discussed, it's important to have an understanding of gradient descent. As a quick refresher, when training
www.jeremyjordan.me
◆ 목차
◎ Input Normalization vs Batch Normalization
○ Scaling & Shift
◎ Differences between Training & Evaluation in Batch Normalization
◎ Benefits of the Batch Normalization
◎ Batch Normalization in Pytorch
◎ Input Normalization vs Batch Normalization
모델에 input으로 들어가는 각 Feature는 서로 그것이 의미하는 물리량이 다르기 때문에, 단위가 다르다.
가령, '연봉', '키', '나이', '몸무게' 라는 Feature가 있을때,
Input에 아무런 짓도 하지않고 모델에 학습을 시킨다면, 가장 숫자단위가 클 수 밖에없는 '연봉' Feature의 영향이 가장 클 수 밖에 없다.
그래서 모든 input Feature에 대해 학습의 진행과정에서 동등한 척도로 영향을 미칠 수 있게 하는 것이 바로
Input Normalization이다.

-> 그렇다면 Batch Normalization은 무엇일까?
Input Dataset 전체에 Normalization을 진행하는 것이아니라,
Gradient가 Update되는 최소단위인 각 Batch단위로 Normalization을 진행해 주는것을 의미한다.

아래 그림을 통해 좀더 자세히 들여다 보면,

Mini Batch 안에있는 B개의 Record단위로
각 Feature끼리의 Normalization이 진행된다.
○ Scaling & Shift
위 그림의 Text에서 나온 말처럼 , Zero-mean, Unit Variance로 모든 Data Feature를 Normalization해준다면,
Feature가 가지고있는 Expression Power가 떨어질 수도 있다.
그래서 이를 적절하게 Scaling해주고, Shift해주는 것이 필요한데 그 식은 아래와같다.

* 그리고 이 때, B와 r는 Batch 마다 학습되는 Learnable Parameter이다.
◎ Differences between Training & Evaluation in Batch Normalization
Batch Normalization에서, 이쯤되면 한가지 궁금해지는 점이,
Batch Size라는 건 학습시에서나 의미가 있는 것인데 Testing 상황에서는 어떻게 작동시켜야 맞는가?
에대한 내용이다.
Testing상황에서는 1개 Record의 값을 보고싶을 수도있고, 10개일수도, 100개일 수도있고..
이럴땐 Batch Size를 정할 수 있는데 어떻게해야하는가?
-> Batch Normalization기법에선 이런 문제점을 지수이동 평균 (Exponentially Weighted (Moving) Averages)를
사용하여 해결한다.
... Mean값과 Variance값을 정할 수 없으니, 이를 이전의 값들과 현재 Testing에서 받아들이는 값과의 이동평균을 통해 정해주는 것이다.
-> 이말은, Testing시마다 약간씩 Mean, Variance값이 달라지므로, Testing진행마다 약간씩 다른모델이 된다는 말이 된다.(근소한 차이겠지만)

* Moving Average에 대해서는 지난번 Optimization 포스팅에서 다루었는데, 아래 첨부해두겠다.
https://roboharco12.tistory.com/27
Deep Learning (6) _Optimization
Neural Network는 Cost Function의 최솟값을 Optimal Point로 도출하고, 이를 Analytic Solution이 아닌, 'Iterative Solution'으로 찾는다. -> Gradient Descent Iterative Solution은 Analytic Solution 처럼 함..
roboharco12.tistory.com
◎ Benefits of the Batch Normalization
지금까지 Batch Normalization기법이 어떻게 진행되는지 알아보았는데,
Batch Normalization을 진행해줌으로서 모델이 좋아지는 점은 아래와 같다.

-> training 속도가 빨라지고, Learning Rate가 좀더 높아져도 수렴이 가능해지며, Weight Initialization에 큰 영향을 받지 않게되고, Regularization(Drop Out, Penalty Term.. etc) 기법의 효과와 같은 효과가 난다.
* 참고: 보통 Drop Out과 Batch Normalization은 둘중 하나만 사용되는 경향이 있다
(서로 대신 사용하는 느낌)
이렇게 되는 이유는,
Optimization이 진행되는 Cost Function이, 더 학습되기 좋게 바뀌기 때문인데,
이런 상황은 대략 아래 그림처럼 표현할 수 있다.

전체적인 Costfunction Landscape를 보다 더 Smooth하게 펴줌으로서,
보통 Optimization에서 말썽을 일으키는 Local Optimum과 Plateau를 없애주는 효과가 나기 때문에,
위와같은 Benefits이 생기는 것이다.
◎ Batch Normalization in Pytorch
Pytorch Package에서는 Batch Normalization을 쉽게 구현할 수 있도록 torch.nn안에 아래 클래스가 구현 되어있다.


https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm1d.html
BatchNorm1d — PyTorch 1.11.0 documentation
Shortcuts
pytorch.org
https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html
BatchNorm2d — PyTorch 1.11.0 documentation
Shortcuts
pytorch.org
위에서 설명했듯,
아래 그림처럼 BatchNormalization Module을 Nonlinear Activation Function앞에 붙여주면 된다.
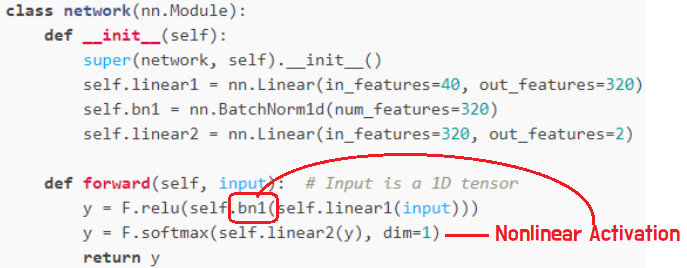
그리고, Drop Out 기법에서 처럼,
Train시에는 model.train(),
Test시에는 model.eval()을 붙여주어서 Model이 어떤 Mode로 동작할 것인지 명시해주어야한다.


'AI > Deep Learning' 카테고리의 다른 글
| Deep Learning (9)_Convolution Layer (0) | 2022.05.22 |
|---|---|
| Deep Learning (8)_Tensorboard & Tuning Parameter (0) | 2022.05.21 |
| Deep Learning (6) _Optimization (0) | 2022.04.23 |
| Deep Learning (5) _ Practical Aspect (0) | 2022.04.22 |
| Deep Learning (4)_DNN (Deep Neural Network) (0) | 2022.04.21 |



