
정리노트
Deep Learning (4)_DNN (Deep Neural Network) 본문
지금까지 포스팅에서 다룬 내용은
뉴런 노드 하나(Linear Regression + Activation Function)부터 시작해서
Shallow Neural network를 일일이 직접구현을 해봤고,
pytorch Framework를 보면서 이 과정이 얼마나 쉽고 간단하게 요약되는지 까지 살펴보았다.
이전까지 다룬 예시는 Layer수가 얕은 Shallow Neural Network였다면,
이번 포스팅에서 다루고자 하는 모델은 Layer수가 깊은 Deep Neural Network이다.

◆목차
◎ Output Types
◎ Parameters VS Hyper-paramters
◎ Stochastic Gradient Descent (S.G.D) / Mini-batch Gradient Descent
◎ DNN With Pytorch (Feat. MNIST)
○ Data Loading
○ Model / Train / Test
○ DNN with Hyperpararmeter (Sequential, ModuleList)
◎ Output Types
Neural Network를 만들때, Activation Function과 Cost Function은 상황마다 다르다고 말해왔었는데, 아래 내용으로 정리된다.
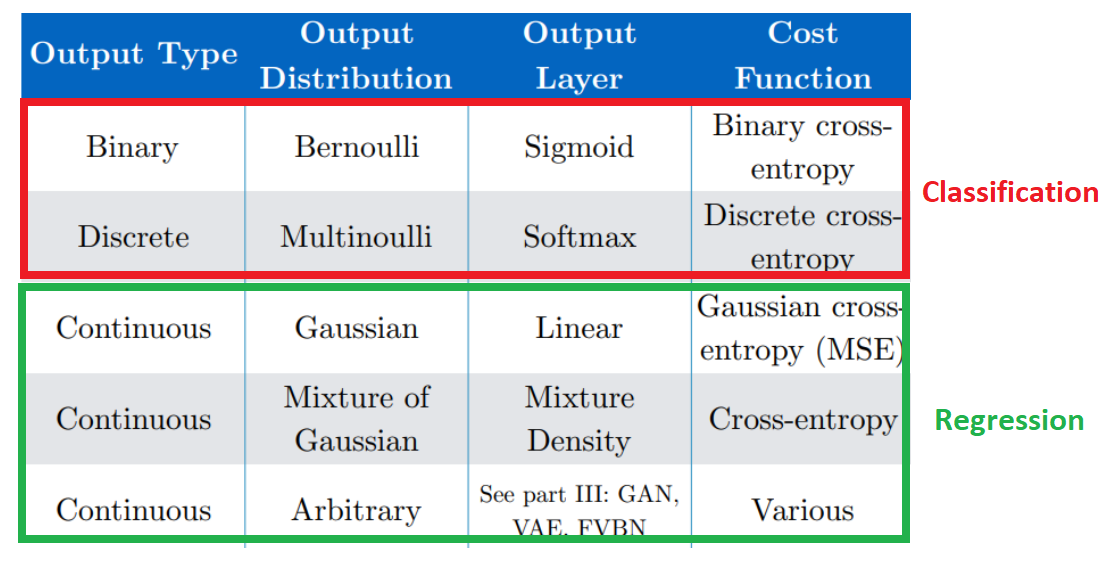
이중, Classification일 경우에, Output Layer의 Activation은
Binary Classification의 경우 Sigmoid,
Discrete(multi Class) Classifiacation의 경우 Softmax Activation Function을 사용하는데,
이에 대한 자세한 내용은 아래와 같다.


◎ (Model) Parameters VS Hyper-parameters
Model Parameter와 Hyper-parameter의 정의는 다음과 같다.

(Model) Parameter의 정의는 Model에 Internal한 Value, 모델의 Data로부터 추출할 수 있는 Parameter라는 것이며,
Hyper-Parameter의 정의는 Model에 External한 Value, 모델의 Data로부터 추출이 불가능한 종류의 Parameter라는 것이다.
그 예시는 위에 적혀있는 것을 참조하면 되는데,
보통 학습과정에서 Update되는것이 아니라,
우리가 외부에서 따로 정의해주어야 하는 Parameter를 Hyper-Parameter라고 부른다.
◎ Stochastic Gradient Descent (S.G.D) / Mini-Batch Gradient Descent
앞선 DeepLearning카테고리에 Linear Regression, Logistic Regression의 Optimization에서 잠깐 다룬 내용이지만,
보통 Optimal point를 찾는 Optimization이
깡으로 Gradient Descent로만 진행되지는 않는다.
속도도 너무느리고, 비효율적이기 때문이다.

Stochastic Gradient Descent와 Mini-Batch Gradient Descent는
Classical한 Gradient Descent 의 문제점을 해결하는 가장 기본적인 방법의 Optimizer이다.
아래 블로그에 자세히 정리되어있으니 참고해보면 좋다.
https://acdongpgm.tistory.com/202
[기계 학습]. SGD 와 mini batch ( 최적화 기법 )
Batch size 의 개념 3명의 학생이 있고 100개의 문제를 주어졌을 때 여러가지 상황이 있다. 1번 학생 ( Batch size == 100 ) : Full-batch 1번 학생은 100개의 문제를 다 풀고 난 뒤 정답을 확인하고 수학문제 정.
acdongpgm.tistory.com
혹시 배치사이즈개념을 잘 모르고 있다면 아래 블로그 참조.
딥러닝-6.2. 최적화(3)-학습 단위(Epoch, Batch size, Iteration)
이전 포스트에서는 경사 하강법의 한계점에 대해 학습해보았다. 이번 포스트에서는 경사 하강법의 실행 과정을 살펴보고, 기본 사용 방법인 배치 경사 하강법(Batch Gradient Descent)이 어떤 단점을
gooopy.tistory.com
블로그 내용들을 살펴보면 쉽게 파악할 수 있는 개념이니 여기서는 간단히 짚고만 넘어가도록 해보자.
먼저 Gradient Descent와 Stochastic Gradient Descent의 차이에 대해 살펴보면

일반적인 Gradient Descent에서는 전체 training Set의 loss 평균값으로 학습시키지만(Full Batch),
Stochastic Gradient Descent에서는 1개의 Training Sample을 Random하게 골라서
(..정확히는 Randomly Shuffled Data를 순차적으로 뽑아서)
바로바로 학습시켜주는 알고리즘을 말한다.
데이터셋 하나하나에 일일이 반응하다보니 S.G.D는
Update는 매우 빠르나 학습이 불안정하다는 단점이 있다.
이런 단점을 보완하는게 바로 Minibatch Gradient Descent이다.

Full Batch(GF)나 One Batch(SGD)가 아니라,
Mini-Batch단위로 학습을 돌려서 Gradient값의 평균을 Back Propagation해주는 것으로,
일반적으로 우리가 학습을 돌릴때 batch size를 선택해주는 과정이 바로 이에 해당한다.


위 그림을 보면 바로 알 수 있는데, Optimal Point를 찾아가는 과정이, 원래의 Gradient 방법 일수록 안정적으로 가고(대신 오래걸리고), S.G.D쪽으로 갈수록 불안정하게 수렴하는 것을 볼 수 있다.
* 불안정하다는 것은 달리말하면 확실하지 않으면 수렴하지 않는 특성으로 작용할 수도 있어서
Local Minima에 잘 빠지지 않는장점이 될 수도 있는 특성이다.
-> G.D는 그만큼 Local minimum에 취약하다는 말이기도 하다.
◎ DNN With Pytorch (Feat. MNIST)
아래는 MNIST Dataset을 학습시키는 일련의 과정들을 담은것인데
가볍게 참조만 해도 좋다.
(물론, MNIST처럼 잘 정돈되어있는 데이터셋을 볼 일은 거의 없고 실제로는 따로 EDA, Preprocessing과정을 거쳐줘야한다.)
○ Data Loading

pytorch는 데이터셋을 불러오는 Dataloader가 존재한다.
이에대한 자세한 내용은 아래 블로그를 참조
https://subinium.github.io/pytorch-dataloader/
[Pytorch] DataLoader parameter별 용도
pytorch reference 문서를 다 외우면 얼마나 편할까!!
subinium.github.io
○ Model / Train / Test

모델설명은 앞부분에서 주구장창 했으니까 생략.
Model을 선언해주고, Loss와 Optimizer를 설정해준후, Training을 돌려주면

이에대해서 Test set을 통해 검증해주면,

Accuracy는

○ DNN with Hyperpararmeter (Sequential, ModuleList)
앞전 Parameters VS Hyper-paramters 부분에서 다룬 개념인데,
Hyper-parameter은 모델의 내부 Data와 관련없는 External parameter를 의미한다.
예를 들어 Learning Rate, Layer개수등이 이에 해당한다.
Deep Neural Network에서 Layer깊이가 깊어지면 깊어질 수록, Hyperparameter를 이용한 모델링을 하는것이 더 깔끔한 코딩이 가능한데, 이를 위해서는 pytorch의 각 모듈을 파이썬의 List처럼 처리하는 nn.Modulelist와 nn.Sequential에대해 알아둘 필요가 있다.
아래 블로그
https://michigusa-nlp.tistory.com/26
pytorch 공부: [nn.Sequential][nn.ModuleList]
10월 안에 CNN-LSTM모델을 짜야 하는데 논문 구현해 놓은 깃허브를 보니 계속 nn.Sequential과 nn.ModuleList가 나와서 정리해야겠다 싶었음. [nn.Sequential] 이것은 입력값이 하나일 때, 즉 각 레이어를 데이
michigusa-nlp.tistory.com

* nn.Modulelist를 사용하지않고 그냥 Python의 list를 이용해 모듈을 아래처럼 묶어버리면,

아래와같은 에러가 난다.

pytorch의 nn.Module이 submodule로 인식하지않아서
Optimizer가 Parameter를 Tracking하지 못한다.
* (참조) nn.Module에서 submodule로 인식하는 case두개
- nn.parameter
- membervariables
'AI > Deep Learning' 카테고리의 다른 글
| Deep Learning (6) _Optimization (0) | 2022.04.23 |
|---|---|
| Deep Learning (5) _ Practical Aspect (0) | 2022.04.22 |
| Deep Learning (3)_ Pytorch (0) | 2022.04.20 |
| Deep Learning (2)_ Shallow Neural network (0) | 2022.04.20 |
| Deep Learning (1) - Linear Regression, Logistic Regression (0) | 2022.04.20 |



