
정리노트
Deep Learning (5) _ Practical Aspect 본문
이번 포스팅에서는 딥러닝 네트워크를 구축하면서 염두해두어야할 내용들에 관한 내용이다.
Deep Learning에 국한되어 적용되는 개념들은 아니고, Machine Learning Algorithm에서도 전반적으로 알고있어야하는 내용들이니, 한번 쭉 보고 모르는 내용이 있으면 잠깐 참고해보면 좋을 듯 하다.
◆목차
◎ Train / Dev / Test
○ Mismatched Train / Test Distribution
◎ Bias & Variance
○ Basic Recipe for Machine Learning
◎ Regularization
○ Regularization Term
○ Drop Out
○ Other Regularization
◎ Normalization / Initialization
◎ Train / Dev / Test
일반적으로 Machine Learning 알고리즘을 접해본 사람이라면, 학습시 Train, Test 셋을 나눠줘야 한다는 사실정도는 알고 있을 것이다. 그런데 알고리즘에 따라서, test set 뿐 아니라 validation set 까지 추가로 두어야 하는 경우가 있는데,
Deep learning 알고리즘이 가장 대표적이다.
대부분의 Deep Learning 알고리즘은 local minima나, Overfeeting 문제에 아주 민감한 모델이기 때문에,
Training 중간중간 과정에 관여되지 않은 Test Data Set을 이용해 Hyperparameter를 중간중간 Tuning하는 경우가 많다.
이런경우 test set이 학습과정에 관여가 된 것이기 때문에, 엄밀한 의미에서의 정확도를 이야기 하려면
최종 Performance Measure하는데 쓰일 별도의 데이터셋을 분리시켜주어야한다.
이런 데이터셋을 Development Dataset, 혹은 Validation Dataset이라고 한다.

* 데이터셋 비율은 8:1:1이거나, 7:2:1이거나, 6:2:2거나.. 는 학습시키는 사람 마음이지만,
수십, 수백만개의 Big Data를 다루는 현대에 와서는 결과 확인하겠다고 Test Data에 만개씩 때려넣지는 않기때문에,
이 비율은 상황마다 다르게 그냥 적용시켜주면 된다.
○ Mismatched Train / Test Distribution
만약, 고양이인지 아닌지 판단하는 딥러닝 모델이 있다고 해보자.
고양이를 학습시키기 위해서는 구글에서 아래처럼 여러 고양이 사진을 모으고 이를 학습시킬 것이다.

그런데 만약 이 모델이 쓰이는 환경이, 수집된 데이터와 다른 환경이라면 어떻게 해야할까?
예를들어 구글이미지를 통해 학습시킨 모델인데, 휴대폰 이미지로만 판단하게 되는 모델이라면...
-> 휴대폰으로 찍은 사진만 따로 모아서 데이터셋을 구축하면 좋겠지만 그렇게 할경우 모을 수 있는 데이터가 한정적이고, 비효율 적이다.
결론을 이야기하자면,
Dev Dataset에는 다른 환경에서 수집된 데이터를 가져와 주고, Training Set에서는 기존에 모았던 데이터들로 학습을 시켜주면 된다.아래 블로그에 이에 대한 내용이 잘 정리되어 있다.
WEEK5 : traning set과 dev/test set의 불일치
1. training set과 test set이 다른 경우 두 가지의 데이터를 수집했다. 웹페이지의 데이터 200,000장 (고화질, 프로페셔널한 사진) 모바일앱의 데이터 10,000장 (저화질, 아마추어의 사진) 실제 서비스를
hyoeun-log.tistory.com

◎ Bias & Variance (Model Capacity)
Bias와 Variance의 Trade Off관계는 Machine Learning 전반에서 알아둬야할 내용중 하나이다.
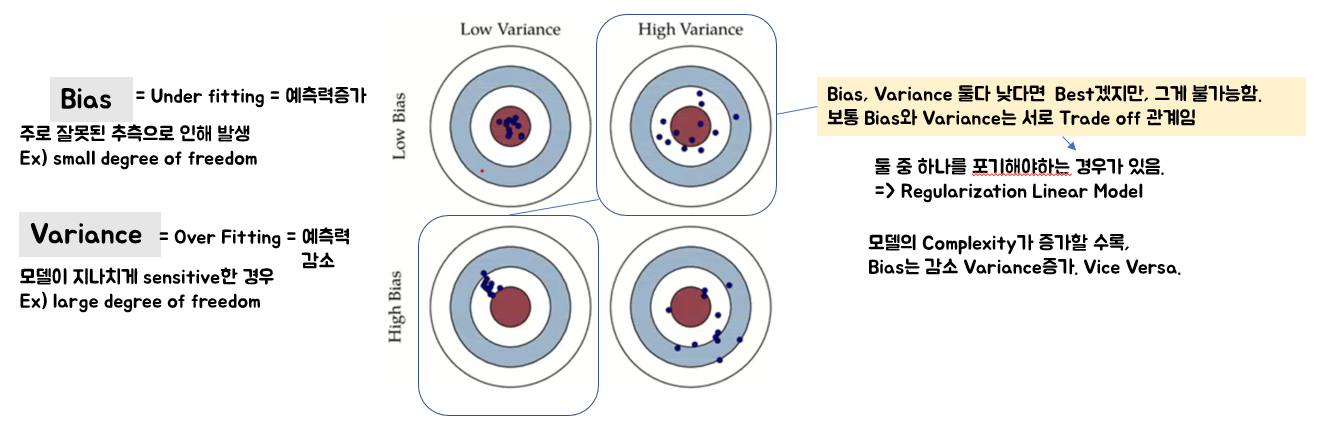
Bias, Variance와 Model Capacity가 무엇인지는 여기서 자세히 다루지는 않겠다.
(아래 블로그를 참조)
쉽게 이해해보는 bias-variance tradeoff
데이터에 기반한 modelling을 할 때 자주 나오는 개념인 bias-variance tradeoff. 중요하지만 헷갈릴 수 있는 개념인데 쉽게 정리된 글을 Quora에서 발견하여 번역하여 공유한다. 원문: How would you explain th..
bywords.tistory.com
Overfitting과 Underfitting 정의 및 해결 방법
만약 동일한 점들이 주어지고 이 점을 대표할 수 있는 함수(곡선)을 추정하는 경우에서, 가운데가 optimize하다고 한다면 왼쪽은 지나친 단순화로 인해 에러가 많이 발생해 underfitting이라 합니다.
22-22.tistory.com
자세한 설명들은 위에 블로그를 참조하고,
여기서는 아래 결론에대한 내용만 다루겠다.

Decision Boundary로 bias, Model, Variance에 관한 내용을 본다면 위 그림과 같다.
직관적으로 이해가 쉽다.

고양이인지 개인지 구분하는 Classification Model에서, 결과값을 보고 Bias, Variance를 판단한다면 위와 같다.
Bias는 Training Set이 얼마나 모델이 합리적으로 판단을 내리는지에 대한 척도로 생각하면 되고,
Variance는 Validation Dataset에 비해서 Train Set이 얼마나 정확한지.
즉, 그 둘의 차이가 얼마나 큰지에 대한 판단 척도라고 생각하면 될 것 같다.
-> 데이터셋 자체의 변동성이 크기때문에 training셋의 복잡도를 따라간다고해서 test셋의 복잡도 까지 커버가 불가능하다는 의미가 됨
-> model capacity가 모자라다! 고 표현이 되는것이 이러한 이유.
*일반적으로 Bias, Variance의 관계는 Trade Off관계라고 한다.
○ Basic Recipe for Machine Learning
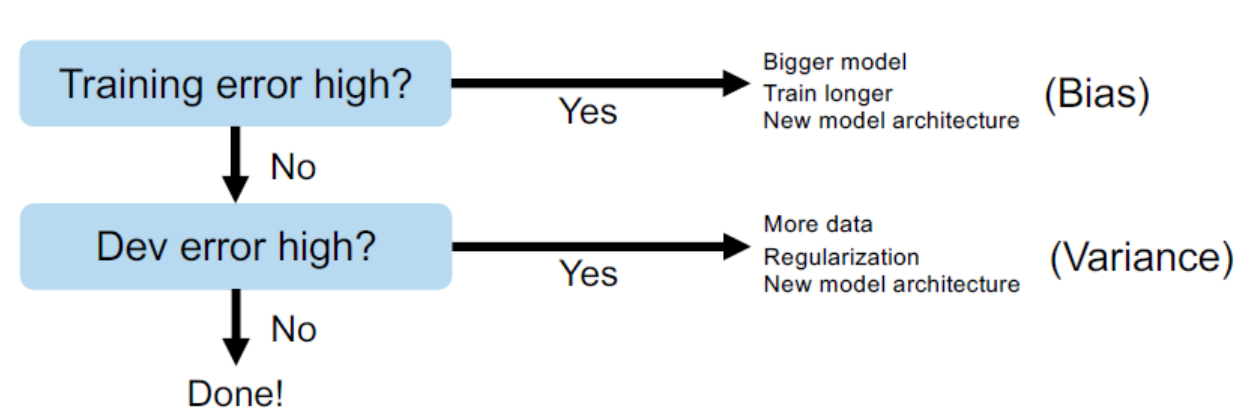
◎ Regularization
Neural Network는 많은 Network들이 얽히고 섥힌 모델이기 때문에,
기본적으로 Model Capacity가 큰 경우가 많다. (Deep Neural Network일 수록 특히나)
그래서 보통 Overfitting하지 않도록 노력을 기울이는 경우가 많은데,
Gradient Descent과정에서 Cost Function에 Regularization Term을 추가하여 weight를 줄여주거나, 혹은 노드 자체의 개수조절을 하면서 Regularization을 진행해 준다.
○ Regularization Term
먼저, Cost Function에 Regularization Term을 추가하는 방식에대해 먼저 알아보자.
(이를 제대로 이해하기 위해서는 좀 딥하게 들어가야 하는 내용이 많은데, 자세히 다루지는 않겠다)
아래와같이 노드가 구성되어 있다고 하자.

여기서, 만약 데이터의 Feature개수가 너무 많아 차원수가 너무 높다면, Regularization Term을 추가하여 Weight를 줄여줄 수 있는데, 이때 Regularization 제약조건으로 L1, L2 에 대한 제약조건이 있다.
(자세한 내용은 아래 블로그의 Lasso Regression, Ridge Regression을 참조)
https://sanghyu.tistory.com/13
Regularization(정규화): Ridge regression/LASSO
이 강의를 보고 정리한 내용이고 자료도 강의에서 가져온 자료임을 밝히고 시작한다. 이전 포스팅에서 살펴본 linear regression 모델을 다시 살펴보자. 이렇게 least square solution을 구하면 너무 모델
sanghyu.tistory.com
예시로 간단하게 L2 Norm에 대한 Regularization을 써보면

Pytorch에서도 이를 구현해놓았는데, Optimizer를 initialization해주는 과정에서 아래와 같이
weight_decay파라미터를 설정해주면 된다.(0: Defalut.. L2 Penalty)

○ Drop Out
Drop Out의 원리는 간단하다.
모든 노드를 사용해서 학습하는 기존 Neural Network와 달리,
Training 과정에서 Random하게 p확률의 노드를 제외하고 학습시키고,
최종 Output을 내는 Test 단계에서는 Output Value에 1-p를 곱하여 출력해주는 것이다.
https://heytech.tistory.com/127
[딥러닝] Drop-out(드롭아웃)은 무엇이고 왜 사용할까?
본 포스팅에서는 딥러닝에 있어서 Generalization 기법 중 하나인 Drop-out(드롭아웃)에 대해 알아봅니다. 📚 목차 1. Drop-out 개념 2. Drop-out 사용이유 3. Mini-batch 학습 시 Drop-out 4. Test 시 Drop-out 1..
heytech.tistory.com
위 블로그를 참조하면 이해가 빠를 것이다.

* 마치 Dropout은 몇개의 Neural Network안에 존재하는 Network를 따로 몇부분 떼어내어 학습시킨후,
이를 한방에 Ensemble하여 조합한 것과 같다.
'p'만큼의 노드를 제외한 '1-p'라는 크기의 모델을 학습시키다가 다시 원래크기 '1'로 조합해서 모델의 값을 출력하니,
당연히 출력이 더 커지게된다. 1-p를 곱해주는 것은 원래 출력값으로 Scailing 해준다는 것과 그 의미가 같다.

-> Dropout in Pytorch
Pytorch에서 Dropout의 구현은, nn.Dropout()을 이용한다.
레이어에서의 값이 Activation Function으로 들어가기 전에 nn안에있는 dropout을 사용해주면, 모든 과정이 알아서 진행된다.

여기서 주의해야할 점이 몇가지 있다.
1, 코드상 Activation Function을 통과하기전에 Dropout을 해줘야 함.
2, Dropout을 사용하면
아래그림처럼 Train시에는 model.train(), Test시에는 model.eval()를 명시해 주어야 한다.
Dropout은 학습상황에서는 p비율 만큼의 노드, Test 상황에서는 전체노드를 사용하기 때문인데,
위 메서드를 명시하는 것에 의미는
학습모드에서는 드롭아웃을 사용하고, (dropout = True) -> p비율만큼의 노드만 사용하겠다
검증모드에서는 사용하지 않겠다 (dropout = False) -> 전체노드를 사용하겠다. 대신 출력에 1-p를 곱하겠다.
는 의미이다.

만약 model.eval()을 명시하지 않고 Test를 하면 아래 그림처럼 정확도가 낮게나온다.
-> training모드의 p개의 노드를 제외한 모델을 사용한 것이기 때문.

○ Other Regularization
Regularization에서 어쩌다가 글이 길어졌는데,
간단하게 두가지정도만 더 언급하고 마무리 해보도록 하겠다.
-> Data Augmentation
https://tunsi-niley.tistory.com/78
Regularization 3 - Data Augmentation
data augmentation은 엄밀히 regularization 기법이라 하긴 어렵지만 비슷한 효과를 가져와서 이렇게 구분을 해보았다 https://arxiv.org/pdf/1806.03852.pdf 소프트웨어적으로 training data를 늘려 과적합을 막..
tunsi-niley.tistory.com

-> Early Stop
https://quokkas.tistory.com/37
pytorch에서 EarlyStop 이용하기
Early Stopping Example 출처 - Early Stopping for PyTorch by @Bjarten(github) 설명과 주석을 일부 한글로 번역하였습니다. 원저자의 'pytorchtools.py'를 직접 페이지에서 다운로드 가능합니다. 이 노트북에서..
quokkas.tistory.com
◎ Normalization / Initialization
○ Normalization
데이터는 각 Feature마다 대부분 Scale이 다를 수 밖에 없다.
예를들어
키,나이, 몸무게, 월수입 4가지 Feature가 있을때, 월수입에 대한 숫자가 다른 Feature보다 월등히 크게되므로,
학습에서 끼치는영향이 다른 Feature에비해서 압도적으로 클 수밖에 없다.
이런 상황을 피하고자 학습전에 보통 input Feature에 대한 Normalization을 진행한다.
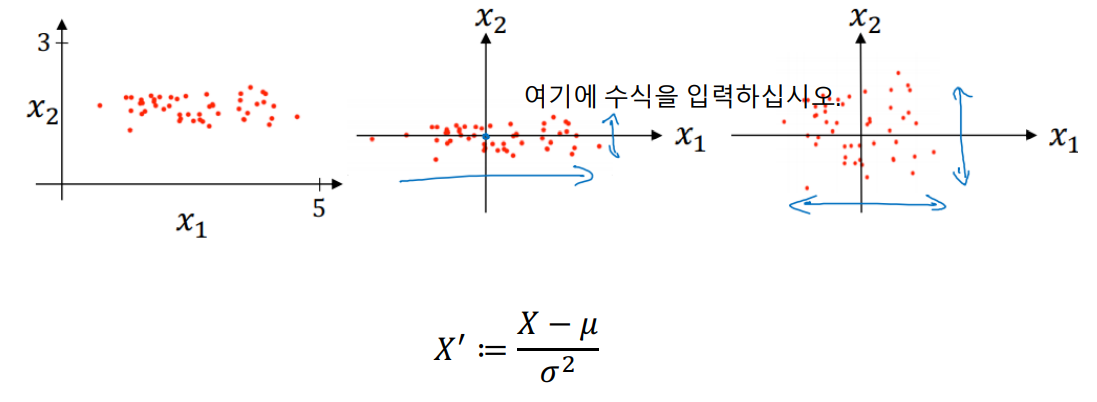

○ Initialization
Neural Network의 학습과정은 구불구불한 Costfunction이라는 산에서 가장 낮은 지점을 찾아 한발자국씩 움직이는 것과 같다. initialization은, '어느지점에서 산을 내려올 것인지'에대해 정하는 것과 같다.
보통 우리가 내려가야할 Costfunction은 정말 복잡한 모양을 띄고 있기때문에
학습의 출발지점에 따라서 성능이 왔다갔다 할 수 밖에 없다.
(...Local Minima)
이에 대해서 정형화된 몇가지 Initialization 방법들이 있는데 아래에 적어둔 내용들을 참조하자.
* n in = input Dimension
n out = output Dimension
- Sigmoid, Tanh Activation Function을 사용할때 initialization
-> Xavier Initialization

- ReLU Activation Function을 사용할때 initialization
-> He Initialization

- Bias Initialization

pytorch에서는

위에서처럼 구현해주면 된다.
'AI > Deep Learning' 카테고리의 다른 글
| Deep Learning (7) _Batch Normalization (0) | 2022.05.21 |
|---|---|
| Deep Learning (6) _Optimization (0) | 2022.04.23 |
| Deep Learning (4)_DNN (Deep Neural Network) (0) | 2022.04.21 |
| Deep Learning (3)_ Pytorch (0) | 2022.04.20 |
| Deep Learning (2)_ Shallow Neural network (0) | 2022.04.20 |



