
정리노트
DRL_Introduction_(3) Value Based Approach_1 본문
https://www.youtube.com/watch?v=dw0sHzE1oAc&list=PLldiB_QS6edl3h831ZrSG8crEWOvPWeun&index=4
발표자료
https://www.slideshare.net/NaverEngineering/introduction-of-deep-reinforcement-learning
Introduction of Deep Reinforcement Learning
발표자: 곽동현(서울대 박사과정, 현 NAVER Clova) 강화학습(Reinforcement learning)의 개요 및 최근 Deep learning 기반의 RL 트렌드를 소개합니다. 발표영상: http://tv.naver.com/v/2024376 https://youtu…
www.slideshare.net
지금까지 포스팅에서
강화학습이 풀고자하는 문제상황의 가장 큰 특징은 'Sparsed- Delayed Reward'임을 정의하고,
이를 해결하는 수학적 계산방법인 MDP의 'Expected Sum of Future Reward'를 계산하는 과정을
Expected, Sum, Future로 나눠서 하나하나 따져가며 정리해보았습니다.
이번 포스팅에서는 더 나아가서
Reward와 State, Action을 어떻게 설정하여 Policy를 알아내는건지에대해 다뤄볼텐데요,
그중 전통적이고도 가장 대표적인 방식인 'Value'개념을 도입해서 Policy를 찾는
"Value Based Approach"에 대해 정리해보도록 하겠습니다.
◆ 목차
◎ What is the Value Based Approach?
◎ Value Function
◎ What is the Value Based Approach?
Value Based Approach에서 말하는 Value란, "Sum of Future Reward" 값인 G(t)를 말하는데,
"Policy를 정의할 때 주변 Value가 높은쪽으로 행동하도록 하면, 결국 미래에 얻는 Reward가 가장 크게 된다",
조금 더 넓은 의미로
"Policy를 정의할때 Value를 사용해서 결정한다"
는 의미를 가진 접근법입니다.
아래 Gridworld로 더 자세히 설명해보겠습니다.
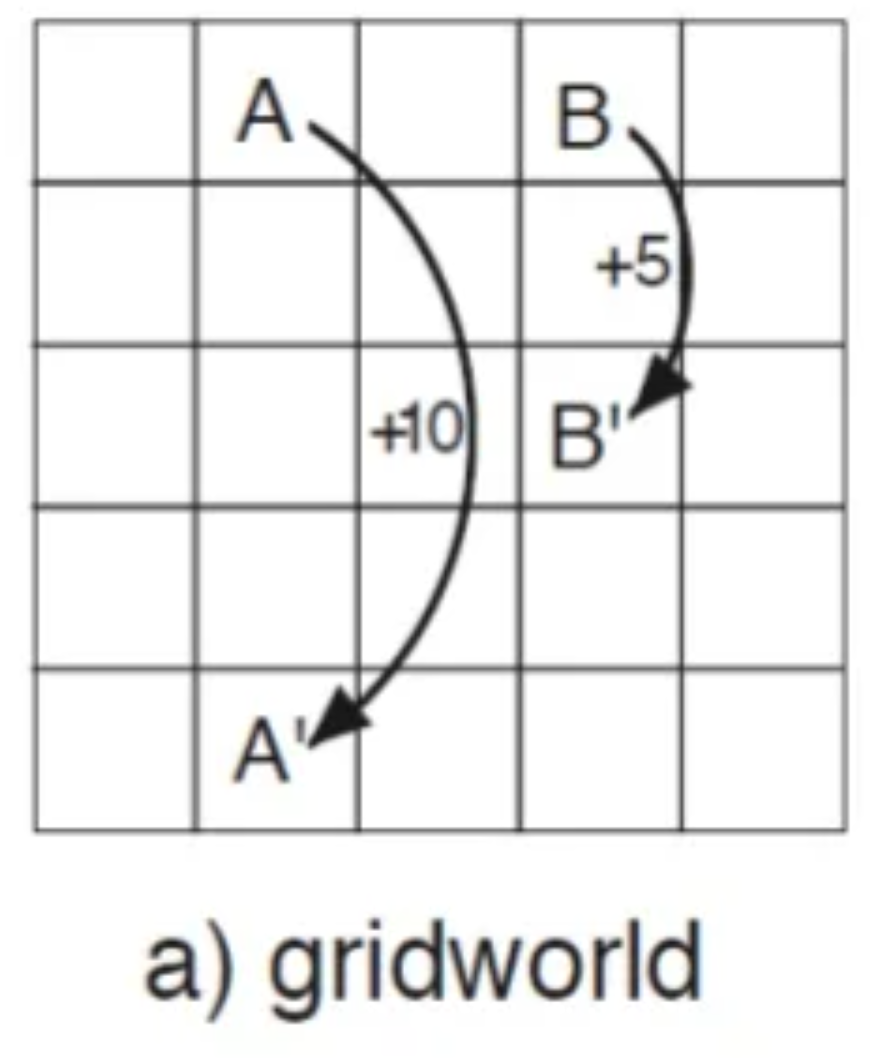
<Action Setting>
- → , ← , ↑ , ↓ 4개로 정의
<State Setting>
- 5X5 개의 Grid
<Reward Setting>
- A Grid에 도달하면 +10점, 그리고 A'로 이동
- B Grid에 도달하면 +5점, 그리고 B'로 이동
- 벽에 부딫히면 -5점
위와같이 Setting이 정의된 Gridworld가 있다고 가정하면,
Optimal Policy는 아래 그림과 같을 것입니다.

Value Based Approach는
위와같은 Policy를 어떻게 만들어내는지에대한 방법론중 하나라고 할 수 있습니다.
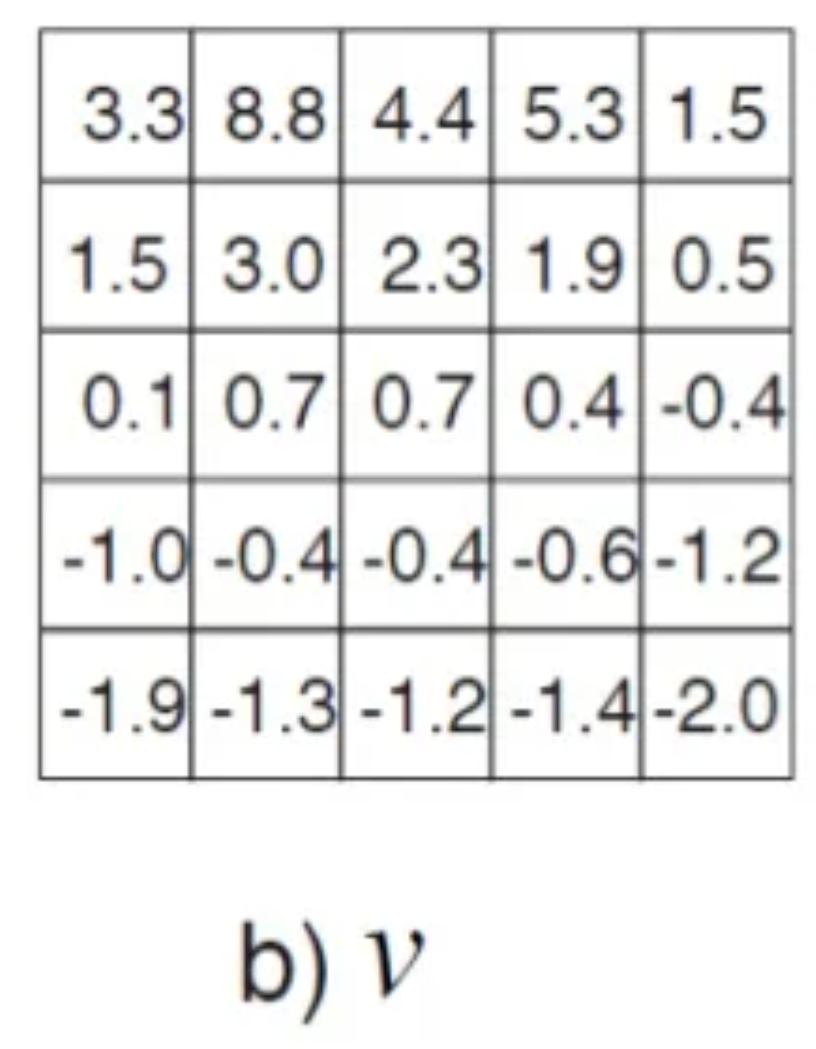
위 그림처럼 각 State의 Value값(Sum of Future Reward)을 두고,
그 다음 State로 어디로 이동할 지 Searching을 할때, 이 Value값을 기반으로 결정하는 것입니다.
이 Value값은 Value Function을 통해 채워지게 되는데요,
아래 섹션에서 좀더 자세히 알아보도록 하겠습니다.
※ Value값을 Function을 통해 정하는것의 의미
Value값을 표가 아닌, Function으로 구하는 이유에 대해서도 잠깐 언급해주셨는데요,
State가 Discrete한 경우도 있지만, Continous한 State를 가지는 경우도 있기 때문입니다.
가령, 256X256 Pixel이미지의 경우 한 Pixel은 실수값을 가지게 되는데, 두 실수 사이에는 무한개의 실수가 존재하므로,
이에대한 State 표는 무한개가 필요하게됩니다.
즉, Continous한 상황도 다룰 수 있도록
Function으로서 Value를 계산 하는것이라고 정리해주셨습니다.
◎ Value Function
아래 그림에 나와있듯이, Value에는 크게 2가지 Function이 있습니다.

이것을 보고 가장 먼저 드는 의문은
State에대한 Value는 알겠는데 Action Value는 왜 필요한가?
일 것입니다. 이에대해 먼저 이야기 해보도록 하겠습니다.
Action Value는
현재 State에서 특정 Action을 행하였을때,
어떤 State로 넘어가게 되는지에대한 확률인 State Transition Probability를 대신하는 역할의 값입니다.

지난 포스팅에서,
State와 State사이에 정의되어있는 Action X,Y 값에대한 State Transition Probability가 있고,
이 확률을 통해 구한 Sum of Future Reward의 기대값을 바탕으로 Policy를 결정한다고 하였습니다.

그리고 이 State Transition Probability는 사전에 정의 된 값이 아니라(그런경우도 있겠지만)
직접 찾아주어야 하는 값이 되는데
한 State에서 다음 State로 가능한 모든 경우의 수에 대한 확률을 찾아주는 것을 영상에서는
'One Step Ahead Search'라고하고,
Unsupurvised Learning을 통해 State Transition Probability를 구하는 강화학습을 방식을
Model Based 강화학습이라고 분류한다고 정리해주셨습니다.
(반대는 Model Free 강화학습이 되겠죠!)
여기서 'One Step Ahead Search'의 문제는
실제 Real World 에서는 "State Transition Probability"를 구하는게 보통은 불가능하다는 점입니다.
*** 여기서 조금 복잡해지는데, 영상에서 든 예시로 설명을 추가로 해보겠습니다.
만일 자동차의 카메라기반 자율주행을 강화학습 알고리즘으로 구축한다고 해봅시다.
여기서 State는 현재 카메라에 들어온 pixel image 되고,
다음 State는 바로 다음 Time Step에 카메라에 들어온 pixel image가 될 것입니다.
그리고 이 이미지 사이 Action은 차량의 핸들과 악셀, 브레이크 값이 되겠죠.
'One Step Ahead Search'의 문제점은
카메라에서 현재 들어오는 pixel image와 Action이 주어지면 그다음 Time Step에 들어오는
pixel image를 모든 환경에 맞게 확률적으로 정의할 수 있어야한다는 것입니다. 불가능하겠죠.
Model Based 강화학습은
'One Step Ahead Search'가 가능할때, 즉, State와 State사이 Action에 따른 관계가
Unsupervised Learning이 가능한 경우이거나, 복잡도가 낮을때 사용 가능한 방식이므로,
매우 제한적인 강화학습 방식이라고 볼 수 있습니다.
(지도학습이 불가능한 이유는, 이걸 Discriminative 한 방식으로 일일이 데이터를 찾아서 학습시키는건
데이터가 무한가지필요할테고, 그 복잡도를 감당할 만한 모델도 없을 것이기 때문입니다)
여기서
Action Value를 도입하면 이런 복잡한 'One Step Ahead Search'를 생략해도 괜찮아집니다.
Action에 대해서도 Reward를 따로 정의해주는 것인데요,
Gridworld에서 이를 표현하면 아래와 같아집니다.
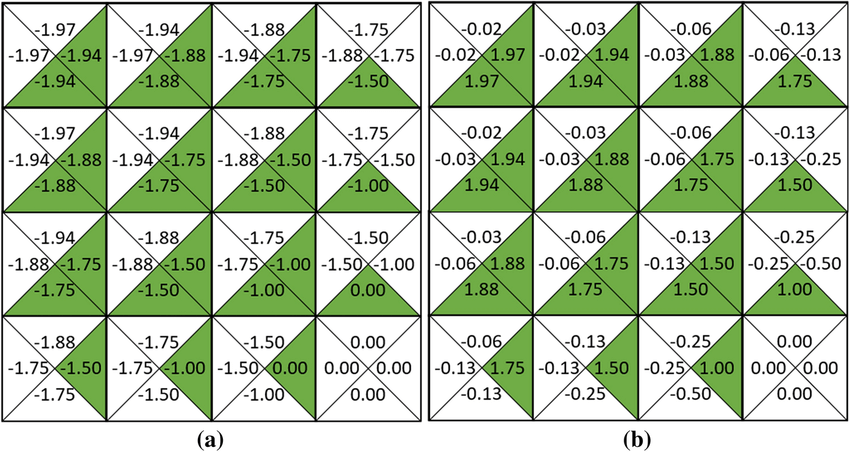
한 Grid내에 행동이 → , ← , ↑ , ↓ 4개로 정의되어 있다면, 각 Action에 대한 Reward가 정의되어 있게됩니다.
이를 통해 State Transition Distribution을 굳이 구하지 않더라도,
해당 State에서 단순히 Greedy하게 Action을 선택함으로서 가장 Optimal한 행동을 파악할 수 있습니다.
그래서 이 Action Value Function을 구해주는게 강화학습의 핵심이라고 할 수 있겠습니다.
...
다음 포스팅에 이어집니다
'AI > Reinforcement Learning' 카테고리의 다른 글
| 단단한 강화학습 Chapter2_(1) _다중선택(Multi-armed Bandits) (0) | 2022.10.01 |
|---|---|
| 단단한 강화학습_intro (0) | 2022.09.30 |
| DRL_Introduction_(4) Value Based Approach_2 (0) | 2022.08.30 |
| DRL_Introduction_(2) Marcov Decision Process_2 (0) | 2022.08.25 |
| DRL_Introduction_(1) Marcov Decision Process_1 (0) | 2022.08.25 |



