
정리노트
DRL_Introduction_(2) Marcov Decision Process_2 본문
DRL_Introduction_(2) Marcov Decision Process_2
Krex_Kim 2022. 8. 25. 22:34https://www.youtube.com/watch?v=dw0sHzE1oAc&list=PLldiB_QS6edl3h831ZrSG8crEWOvPWeun&index=4
발표자료
https://www.slideshare.net/NaverEngineering/introduction-of-deep-reinforcement-learning
Introduction of Deep Reinforcement Learning
발표자: 곽동현(서울대 박사과정, 현 NAVER Clova) 강화학습(Reinforcement learning)의 개요 및 최근 Deep learning 기반의 RL 트렌드를 소개합니다. 발표영상: http://tv.naver.com/v/2024376 https://youtu…
www.slideshare.net
지난 포스팅 (1) MDP 에 이어서 쭉 내용정리해보도록 하겠습니다!!
◆ 목차
◎ Supervised Learning VS Reinforcement Learning
◎ Planning VS Reinforcement Learning
◎ Discount Factor
◎ Deterministic Policy VS Stochastic Policy
◎ Supervised Learning VS Reinforcement Learning
영상에서 지도학습과 강화학습의 중요한 특성에대해 잠깐 언급해주셨습니다.
이를 잠깐 정리해보고 넘어가보도록 하겠습니다
만약 어떤 게임을 수행하는 모델을 만들어야한다고 했을때,

Supervised Learning으로 이를 구현한다고 하면 모든 경우의 가지수에대해 '이럴땐 이런 행동을 해야한다' 라는 정답을 모델에게 학습시키는 것이라고 볼 수 있습니다.
즉, 모든 상황에대해서 가장 Optimal한 행동이 존재하고,
이를 모든 경우의 수에대해 하나하나 학습시켜야 한다는 말인데,이는 불가능합니다.
게임의 특성상 무한가지의 경우의 수가 존재하고, 각각의 정답도 무한가지에 가까울것이기 때문입니다.
이와는 다른방식인 Reinforcement Learning으로 이를 구현할 경우에는,
Reward에 대한 반응이 들어오는 경우만 학습이 진행되게 되며,
이는 지도학습에 비해 매우 'Sparse Label'(Sparse Reward)한 특성을 지닌 학습방법이라고 볼 수 있습니다.
또한 Reward가 즉각적으로 바로 오는 것이 아닌, 10초뒤, 혹은 100초뒤의 상황에 영향을주게 되므로,
"Delayed Reward"한 특성을 가진 학습법이라고도 할 수 있습니다.
=> 영상에서 이러한 강화학습의 중요한 특성을 'Spase & Delayed Reward'라고 한마디로 정리해주셨습니다.
** 훨씬더 복잡한 상황을 잘 컨트롤하는 강화학습이 무조건 지도학습보다 좋을까요?
그건 아닐겁니다.
Supervised Learning와 Reinforcement Learning이 각각 잘 작동하는 상황이 따로 있을텐데요,

input X에 대한 Output이 바로바로 보여질때, Classification이나, Regression의 개념으로 문제를 직관적으로 정의할 수 있을때는 Supervised Learning이 적합한 학습법일 것입니다. 관계가 간단한 만큼이나 input, label Data를 충분히 모을 수 있을것이고, 복잡도를 감당할 수 있는 모델도 충분히 만들어낼 수 있을것이기 때문입니다.

이와반대로,
Reinforcement Learning의 경우, input과 Reward
사이 관계 복잡도가 더 높습니다.
관계 복잡도가 높다는 것을 조금더 자세히 설명해보자면,
지도학습의 경우, input→ Label의 관계가 직접적으로 바로바로 이루어지는 반면
강화학습의 경우, Action → State → Reward의 Trajectory가 지속적으로 계속 이어져서 결국에는 최종 Reward(Label)에 대한 정보가 현재 State에 전달이 될때에만 학습이 이루어집니다.
이러한이유로 각각 학습의 특성을
지도학습 상황의 경우 "Dense & Instant Label",
강화학습의 경우 "Sparse & Delayed Reward"
라고 특정지을 수 있습니다.
◎ Planning VS Reinforcement Learning
이야기를 다시 Marcov Decision Proscess로 돌려보겠습니다.
지난 포스팅에서 자세히 다뤄보았던 Marcov Decision Proscess(MDP)는
크게 "Planning"과 "Reinforcement Learning"으로 나뉘는데요,
Planning에는 Dynamic Programming,
Reinforcement Learning에는 MonteCarlo Method / Temporal Difference Learning(Q-Learning), 등이 있습니다.
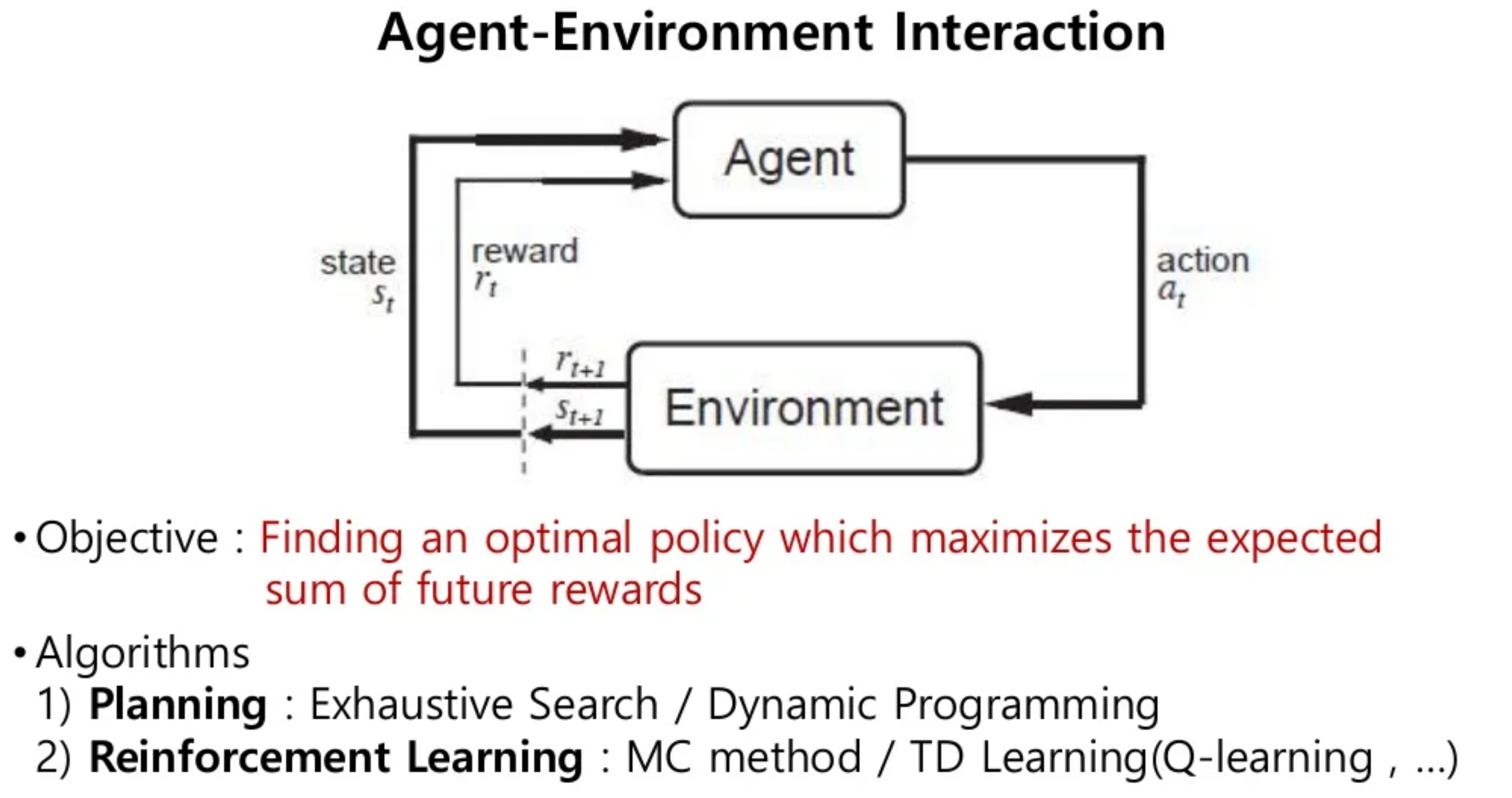
지난번 포스팅에서는 Expected Sum of Future Reward에서 'Future'를 자세히 설명했었는데요,
이번 포스팅에서는 'Expected'에 초점을 맞춰서 보겠습니다.
Planning과
Reinforcement Learning는
바로 이 기대값을 구하는 방법론에 따라 구분지어지는데요,
Planning의 경우 사건의 Prior Probability를 알고있다 가정하고 기대값을 구한 것이고,
Reinforcement Learning의 경우 경험적으로 실제로 관찰된 사건에 따라 그 기대값을 구한 것을 의미합니다.

가령, 주사위를 던졌을때 그 값에 대한 기대값을 구한다고 했을때,
"주사위 모양이 정육면체니까 1,2,3,4,5,6 각각 값에 1/6을 곱하여 더했다!"
라고하면 Planning에 해당하는 기대값 계산법이고,
"주사위 모양이 정육면체에 가까울 수도 있지만 뭔가 오차가 생겨서 다르게 생겼을 수도 있으니,
나는 100번 던져서 직접 평균을 구할것이다!" 라고하면 Reinforcement Learning에 해당하는 기대값 계산법입니다.
즉, 강화학습은 학습을 진행하는데 직접 Agent를 실행시켜가며 Sum of Future Reward의 기대값을 찾는 방법을 말하고,
Planning 기법은 이에대한 Prior Probability를 알고있다고 가정하며 Sum of Future Reward의 기댓값을 찾는 것이라 정리할 수 있을것 같습니다.
강화학습에서 이를 어떻게 적용해서 계산하는지 구체적으로는
다음 "Value Based Approach" 포스팅에서 자세히 다뤄보도록 하겠습니다.
◎ Discount Factor
강화학습에서 MDP의 마지막 퍼즐조각, Discount Factor에 대해 정리해보겠습니다.
Expected Sum of Future Reward를 구할때, 이번엔 'Sum' 하는 방식에대해 초점을 맞춰보겠습니다.
Reward를 다 더할때 그냥 더하는 것이 아니라 시간에 따라 Discount Factor γ를 곱해주는 기법인데요,
이를 3가지 관점에 따라 해석할 수 있습니다.
1,
Discount Factor의 Idea는
"Reward까지 도달하는데에 더 빠르게 도달할 수록 높은 Reward를 가져간다"는 것입니다.
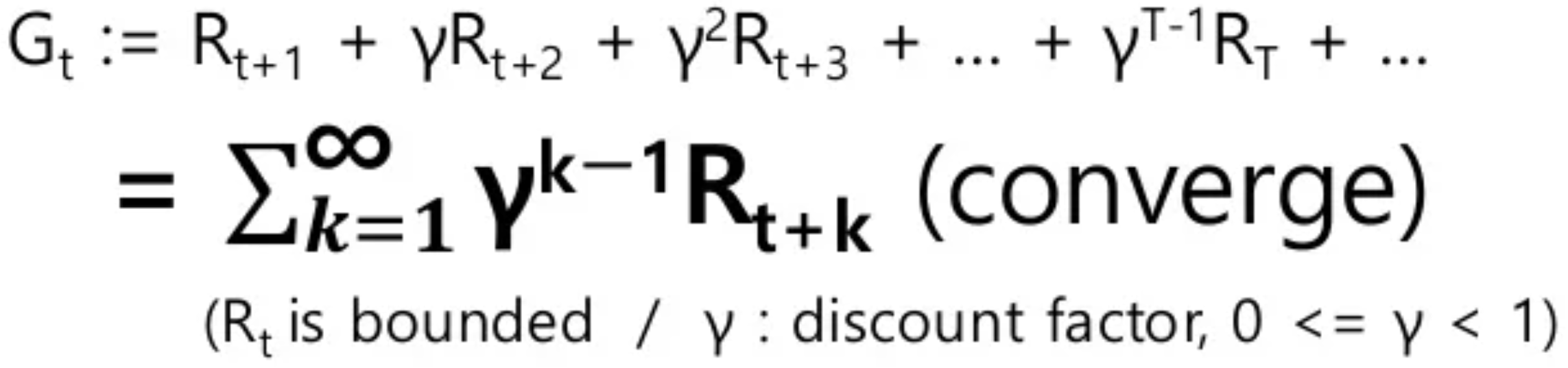
Reward R(t)앞에 1보다 작고 0보다 큰 각 Time Step에 대한 Discount Factor γ를 지속적으로 곱해주면,
time Step이 길어질 수록 γ^t-1 만큼 해당 Reward는 감소하게 됩니다.
=> Discount Factor를 이용하면, Agent가 단기적인 목표를 수행하도록 할것인지, 아니면 장기적인 목표를 수행하도록 할 것인지 조절할 수 있는 것입니다.
**Learnable Parameter은 아니고, 사람이 직접 정해줘야하는 파라미터입니다.
2, 다음과같이 Reward를 구할때 상황을 두가지로 나눠보면,

Episodic Tasks : 끝이 정해져있는 상황과 (미로찾기, 슈퍼마리오 처럼 최종 목적지가 존재하는 상황)
Continous Tasks : 끝이 정해져있지 않은 상황 (주식시장처럼 최종 목적지가 존재하지 않는 상황)
으로 나누어서 볼 수 있습니다.
끝이 정해져있는 Episodic Tasks의 경우, 어떻게든 Expected Future Reward를 정의할 수 있겠지만
끝이 정해져있지 않은 Continous Tasks의 경우, Expected Future Reward는 무조건 무한대로 Diverge하게되어
기대값을 찾을 수가 없게됩니다.
Discount Factor를 적용하면,
Episodic Case건, Continous Case건 상관없이 Converged된 "Expected Sum of Future Reward"를 찾을 수 있게됩니다.
무한 등비수열의 등비가 1보다 작을때 그 합이 수렴하기 때문입니다.
3,
Discount Factor가 지닌 또다른 의미는,
Reward에서 멀어질 수록 가능한 경우의 수가 크게 늘어나면서 Variance가 크게 증가한다고 볼 수 있으므로,
그 Variance를 더 줄이는 방향으로 기대값을 구하겠다고도 해석할 수도 있습니다.
◎ Deterministic Policy VS Stochastic Policy
이번 포스팅에서 다룰 마지막 MDP에대한 내용입니다.
Marcov Decision Process를 통해 얻어진 Policy는 크게
"Deterministic Policy", "Stochastic Policy"두가지 방식으로 나눌 수 있는데,
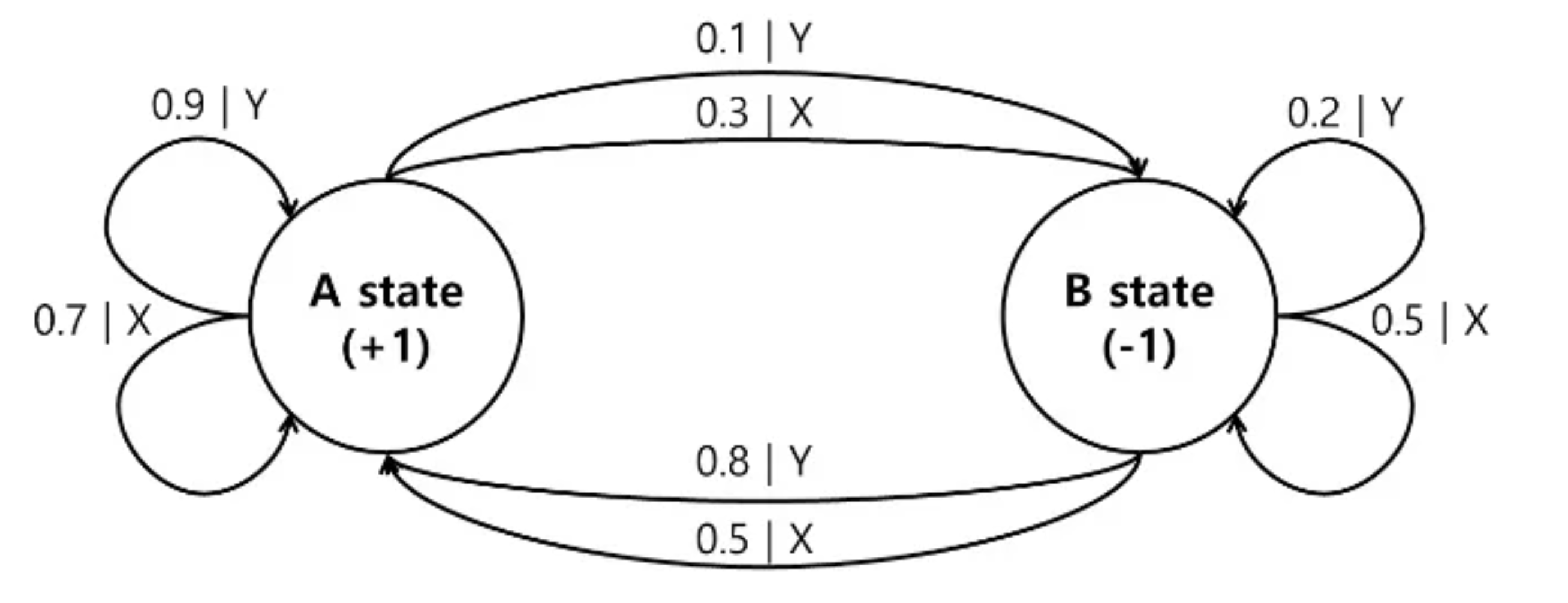
지난 포스팅에서 다뤘던 위와같은 그림의 Environment가 정의된 상황에서,
Deterministic Policy의 경우, '항상 확률이 높은쪽으로만' Action이 정해지는 Policy를 의미하고,
Stochastic Policy의 경우, '확률적으로 Action이 정해지는' Policy를 의미합니다.
'AI > Reinforcement Learning' 카테고리의 다른 글
| 단단한 강화학습 Chapter2_(1) _다중선택(Multi-armed Bandits) (0) | 2022.10.01 |
|---|---|
| 단단한 강화학습_intro (0) | 2022.09.30 |
| DRL_Introduction_(4) Value Based Approach_2 (0) | 2022.08.30 |
| DRL_Introduction_(3) Value Based Approach_1 (0) | 2022.08.27 |
| DRL_Introduction_(1) Marcov Decision Process_1 (0) | 2022.08.25 |



