
정리노트
Deep Learning (12)_CNN_3 : ResNet 본문
https://arxiv.org/abs/1512.03385
Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with
arxiv.org
2015년 위 논문이 발표되고
image Classification분야에서 혁신을 일으켰던 ResNet,
지금까지 CNN에서 다루었던 중요 개념들을 이용해 이를 이해해보도록 하자.

image Classification에서..
사람보다도 에러율이 낮은 경이로운 정답율을 보인다..

◆ 목차
◎ ResNet Concept
○ Skip Connection
◎ why it works?
◎ ResNet Details
○ 1X1Convolution Downsampling
○ Bottleneck Architecture
◎ ResNet Concept
Neural Network가 Deep해 질 수록, 늘어난 Layer 개수만큼 Back Propagation의 Chain Rule 길이가 길어지게 된다.

34개의 Layer로 되어있는 위 그림을 살펴보자.
Back propagation은
Loss를 Weight로 Partial Derivation한것을 이용해 각 Layer의 Weight Update
-> Weight변화가 Loss감소를 얼만큼 일으키는지의 변화량을 구할때 ChainRule을 활용함
이런 Chain Rule은 아래와 같은 과정을 거친다

... Activation Function과 Layer 노드 output a의 Derivation을 반복적으로 곱하여 구하고,
각 노드에서의 가중치에대한 Loss변화량을 Gradient로 삼아서 Weight업데이트를 하는식
이 Back Propagation은... Deep Neural Network에서 적용하기가 매우 어려운데,
기울기가 1보다 작은 Activation Function을 사용한 경우엔 Gradient Vanishing현상으로 인해 학습 진행이 매우 어렵고,
(Layer개수만큼 Gradient값이 곱해지는데, 각 Gradient는 1보다 작기 때문에 최종값이 거의 0에 수렴한다)
ReLU를 사용하더라도 깊이자체가 너무 깊기때문에,
한번이라도 Node의 Activation Function에 전달되는 값이 0보다 작으면 그 뒤 Node의 네트워크 전체가 죽어버린다.

https://velog.io/@yunyoseob/Gradient-Vanishing-%EA%B8%B0%EC%9A%B8%EA%B8%B0-%EC%86%8C%EC%8B%A4
Gradient Vanishing : 기울기 소실
오늘 포스팅할 2번째 키워드로 공부하는 데이터 분석의 키워드는 Gradient Vanishing입니다.퍼셉트론이란 입력층과 출력층으로만 구성된 최초의 인공신경망을 의미합니다.사진출처 : 딥러닝을 이용
velog.io
(자세한 내용은 위 블로그 참조)
즉,
죽은 Network들이 많아짐으로 인해 모델 전체의 Bias Error가 증가하고,
아래와같이 학습이 오히려 제대로 일어나지 않는다.

(착각하면 안되는게, Overfitting이랑은 엄연히 다른 것이다 -> 애초에 Training자체에서부터 에러율이 올라간다.)
ResNet이 처음 제시된 것은 Extremely Deep한 Network에서도 Training이 쉽게 이루어지도록,
Gradient Vanishing 현상을 막을 수 있도록 하기 위해서 제시되었다.
○ Skip Connection
ResNet은 Residual Network의 줄임말이고, 여러개의 Residual Block을 쌓아서 만든 Network구조를 띄고있다.
Skip Connection은 이러한 Residual Block의 핵심개념인데,

그림으로 표현하면 아래와 같다.


일반적인 Neural Network는 Activation Function을 통과하는 값이 직전Layer input과 해당 노드의 Weight가 곱해진 값만이 들어가지만, ResNet은 그 전전 노드의 Output값까지 더해서 Activation Function을 통과하는 구조로 되어있다.
이렇게 했을때 Back Propagation과정에서 Gradient Vanishing현상이 줄어들면서도 모델 자체의 Capacity는 보존할 수 있는데, Gradient가 Back Propagate되는 길이 바로 직전 노드만 있는게 아니라 다른 길로도 전이될 수 있어서
아무리 깊은 Network라고 해도 처음 Layer까지 쉽게 도달할 수 있게되는 것이다.

◎ why does it works?
Residual Block이 Gradient Vanishing 문제를 어떻게 효과적으로 해결했는지 조금 자세히 들여다보자.

일반적인 형태의 Layer를 쌓으면

아래와 같은 식이되지만,
Residual Block형태로 Layer를 쌓으면


이 된다.
만약,

로 Weight가 Update되면..
이전 같았으면 이 Layer와 연결된 아래 모든 Output 값이 0이되어서
그 뒤 네트워크 자체가 죽어버릴텐데,
전 전 Layer의 Output값인

가 아직 살아있기때문에, 네트워크 일부가 죽더라도 전체 네트워크는 죽지않고 살아있을 수 있다.
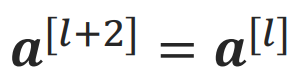
이게 Skip Connection이 Deep Neural Network에서 위력을 발휘하는 이유이다.
-> 필요에따라서 Layer개수가 줄어든것처럼 gradient가 전파되기 때문이다.
◎ ResNet Details
더 자세한 내용을 살펴보도록 하자.
ResNet의 Full Architecture는 아래와 같다.

- 앞서봤던 Residual Layer를 쌓는다.
- Residual Block은 2개의 3X3 Convolution Layer를 가지고 있다.
- Residual Stride는 2, 즉 Convolution Layer 두번을 건너뛴 Layer에 Skip Connection되어있고,
반복적으로 2개의 필터(Convolution+BatchNorm)로 Downsampling시켜주는 구조이다.
- Fully Connected Layer는 맨 마지막 Output Class에 Flatten할때 딱 한번 쓰인다.
- Image Net상황에 딸 23,50,101,152개의 Layer를 사용한다.
위에서 Residual Block을 설명할 때 썼던 Residual Block은 정말 기본적인 형태의 Residual Block이고,
ResNet에서의 Residual Block은 아래와 같이 구성되어있다.

2개의 Convolution Layer, Batch Normalization Layer가 쓰였고, Activation Function으로는 ReLU가 사용되었다.

○ 1X1Convolution Down/Up sampling
위의 식에서 만약, Propagation한 곳의
Channel이다르다면? Width, Height가 다르다면?
어떻게해야할까
먼저 Channel이 다른경우,
-> 1X1 Convolution Layer를 이용해 Down Sampling

그림으로 보면

1X1 Convolutiion Filter를 쓴다니, 무슨말일까?
아래 그림으로 살펴보자.

6X6X32 input에 대해 1X1X32 Convolution Filter를 적용하면
오른쪽 처럼 6X6X1의 2D Matrix가 나오게된다.
다시말해, 이런 1X1 Convolution Filter를 Output Channel 수를 마음대로 맞춰줄 수 있는 것이다.
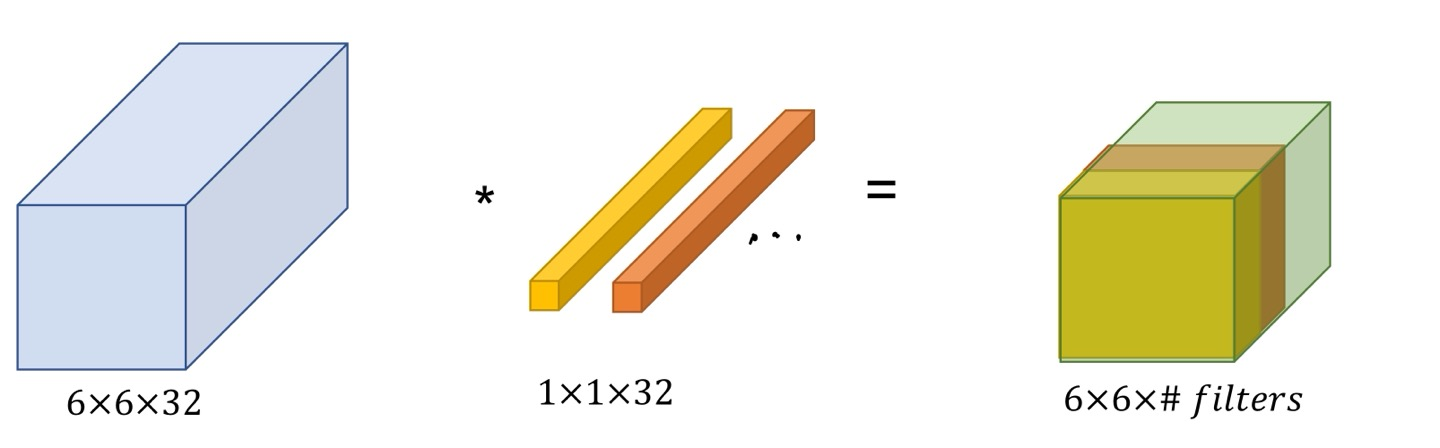
- Width, Height가 다른 경우
일반적으로 Convolution Layer가 차원길이를 줄여나가는 방식처럼, Stride와 Padding을 이용해 줄여나가면 된다.
(조금 상식적인 답변이니 자세한 설명은 생략)
○ Bottleneck Architecture
Output Channel수를 마음대로 조절할 수 있는 1X1 Convolution Filter를 이용해서 만든 Architecture로,
아래 그림과 같이 64개의 Channel로 Downsampling한번 해주고, 3X3 Convolution layer를 적용시킨후 다시 256개의 Channel로 Upsampling해주는 구조로 되어있다.

왼쪽이 일반적인 Residual Block이고, 오른쪽이 Bottleneck Architecture구조가 사용된 Residual Block이다.
오른쪽 그림에서, 왼쪽과 같은 구조였으면
Convolution Layer (3X3X256)를 256개를 가지고 있어야 하므로, 총 파라미터 수는 3X3X256X256.. 이게 두개니까 X2
..
Residual Block 하나에 파라미터수가 너무 많아지게되는데,
BottleNeck구조를 사용하면...
1X1X256 Convolution Filter (Downsampling) 64개와
(3X3X64) Convolution Layer 64개, 그리고
1X1X64 Convolution Filter (Upsampling) 256개
즉, 1X1X256X64 + 3X3X64X64+ 1X1X64X256 (69,632)<< 3X3X256X256X2 (=1,179,648)
이전보다 파라미터 개수가 확 줄어드는 것을 알 수 있다.
https://coding-yoon.tistory.com/116
[딥러닝] DeepLearning CNN BottleNeck 원리(Pytorch 구현)
안녕하세요. 오늘은 Deep Learning 분야에서 CNN의 BottleNeck구조에 대해 알아보겠습니다. 대표적으로 ResNet에서 BottleNeck을 사용했습니다. ResNet에서 왼쪽은 BottleNeck 구조를 사용하지 않았고, 오른쪽은..
coding-yoon.tistory.com
'AI > Deep Learning' 카테고리의 다른 글
| Deep Learning (13)_ Object Detection (0) | 2022.06.18 |
|---|---|
| Deep Learning (11)_CNN_2.. LeNet-5, Alex Net, VGG Net (0) | 2022.05.22 |
| Deep Learning (10)_CNN (Convolution Neural Network)_1 (0) | 2022.05.22 |
| Deep Learning (9)_Convolution Layer (0) | 2022.05.22 |
| Deep Learning (8)_Tensorboard & Tuning Parameter (0) | 2022.05.21 |



