
정리노트
[논문리뷰] Deep Q Network (DQN) 본문
<Arxiv 버전>
https://arxiv.org/abs/1312.5602
Playing Atari with Deep Reinforcement Learning
We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw
arxiv.org
<Nature 버전>
https://www.nature.com/articles/nature14236/?source=post_page---------------------------
--------------------------
이번 포스팅에서 다룰 논문은 DQN으로,
DQN은 High Dimensional한 Sensory Input으로부터 강화학습을 바로 수행하는데 성공했던 첫번째 심층 강화학습 모델이다.
강화학습에서, Agent는 환경으로부터 Reward와 State, 즉 Observation 데이터를 받고 이를 기반으로 다시환경에 Action을 전달하는 형태로 동작하게 되는데,
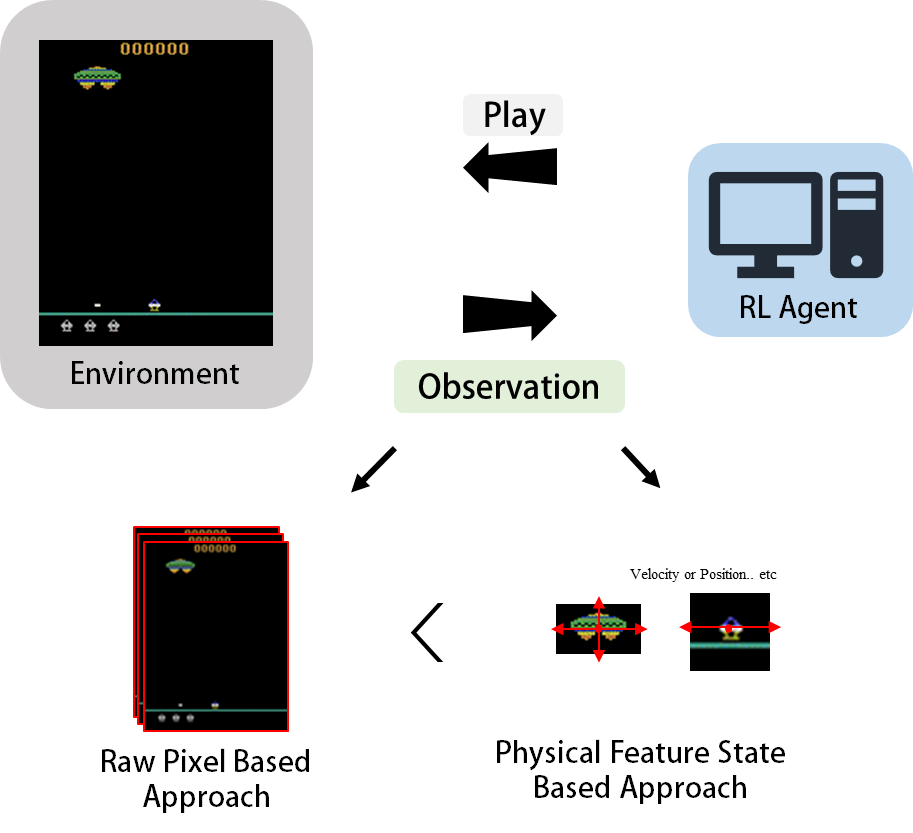
이때 State Observation은 Pixel값 같은 High Dimensional Observation 일수도 있고, 반대로 Physical Information이 담긴, 가령 Object의 속도나 회전, 위치값 같은 정보를 받아들이는 Low Dimensional Observation일 수도 있다.
일반적으로 후자의 Low Dimensional Observation이 전자의 High Dimensional Observation보다 더 학습이 잘되고, Sample-Efficient한 것으로 알려져 있다.

DQN에서 해결하고자 하는 문제는 전자의 High Dimensional Raw Pixel 데이터를 기반으로 학습하는 알고리즘이다.
이전에 이러한 문제를 해결하려는 시도는 여러차례 있었으나, 모종의 이유로 잘 안되었고,
DQN은 기존에 제기됐었던 문제점들을 상당부분 개선하여 성공적인 학습이 이루어진 첫사례의 알고리즘이라고 할 수 있다.
High Dimension을 가진 Raw Pixel 이미지 Input의 Curse of Dimensionality 문제를 2012년 당시 최고성능의 CNN 모델이었던 AlexNet을 통해 극복하였고,
Consecutive Samples학습시 발생했던 Q Maximization bais 문제를 Experience Replay를 도입하여 해결하였으며, 업데이트 타겟값이 계속 이동하는 Moving Target Issue를 Target Network를 별도로 하나더 둠으로서 해결하였다.
◆ AlexNet
2012년은 Image Net Challenge라는 경연대회를 필두로, 이미지 기반 Deep Leaning연구가 활발했던 시기이다.
고차원의 High Dimensional Raw Pixel 이미지 인풋은 Feature개수가 많아 Curse of Dimensionality(차원의저주)문제로 부터 자유롭지 못했기 때문에, 이미지로부터 클래스를 분류해 내는 것이 당시엔 꽤나 어려운 문제였다.
Deep Learning을 통해 이러한 분류문제를 해결하고자 함은, 결국 인풋데이터로부터 Convolutional Layer를 이용해 효과적으로 Feature를 추출하고, 이를 기반으로 간단한 머신러닝 모델을 덧붙이는 것을 의미했다. 이러한 패러다임을 Feature Representation이라고 부르는데, 지금까지도 Deep Learning에서 가장 핵심이 되는 개념중 하나이다.
2012년 당시 가장 성능이 좋았던 CNN 모델을 AlexNet이었고, DQN은 Function Approximation 네트워크로 이 AlexNet을 활용함으로서 High Dimension 인풋을 효과적으로 받아들일 수 있도록 하였다.
<AlexNet: ImageNet Classification with Deep CNN>
https://dl.acm.org/doi/abs/10.1145/3065386
ImageNet classification with deep convolutional neural networks | Communications of the ACM
We trained a large, deep convolutional neural network to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 different classes. On the test data, we achieved top-1 and top-5 error rates of 37.5% and 17.0%, ...
dl.acm.org
(AlexNet에 대한 자세한 설명은 생략)
◆ DQN이전 강화학습에서의 Neural Network 활용 시도
DQN은 엄밀히 말하면, High Dimensional Raw Pixel 데이터를 Neural Network로 받아들여서
가치함수를 근사하는 첫번째 사례는 아니다.
기존에도 몇번의 시도가 있었는데, Action Space가 작음에도 학습이 잘 진행되지 않아서
Case by Case로 문제를 쪼개서 해결하는 방식들이 제안되었다.
아래는 그 예시들이다.
- Neural Fitted Q Iteration - First Experience with a Data Efficient Neural Reinforcement Learning Method(2005)
link.springer.com/chapter/10.1007/11564096_32 - Q-Learning in Continuous State and Action Spaces (1999)
link.springer.com/chapter/10.1007/3-540-46695-9_35 - Reinforcement Learning for robots using neural networks (1993)
www.proquest.com/docview/303995826?pq-origsite=gscholar&fromopenview=true
◆ Reinforcement Learning에서 Neural Network를 효과적으로 사용하기 어려웠던 이유
논문에서 언급된 강화학습에서 Neural Network를 통해 가치함수를 근사하기 어려운 이유는
고차원 Raw Pixel 데이터의 "Curse of Dimensionality"말고도 두가지가 더 있다.
- Data Sample의 Correlation으로인한 Q Value Maximization bais
일반적인 Deep Learning학습에서는 대량의 데이터를 수집한 후, 랜덤으로 Batch Size 만큼의 서로 독립적인 데이터를 샘플링하여 네트워크를 업데이트 시키고, Labeling값 자체도 정확하게 정해진 값을 학습하도록 한다.
하지만 강화학습에서 Neural Network를 학습하는경우 이야기가 조금 달라지는데,
강화학습에서는 데이터가 에이전트가 실시간으로 환경과 상호작용하면서 시간순서대로 쌓이므로, Sample간 시간에 따른 Correlation이 존재하며, 심지어 환경적 변화에 따라서 Reward값에도 Variation이 생기게된다.
이로인해 발생할 수 있는 가장 큰 문제는 'Q Value Maximization bias' 이다.
기존 Q Learning에서 Update식인
Q(s,a)← Q(s,a) + µ*( r+ γ*max_aQ(s`, a`) - Q(s,a) )에서,
Action Value Q(s,a) 와 Target Value r+ γ*max_aQ(s`, a`)가 상당한 Correlation이 있기때문에, 실제로는 매우 비슷한 Q값을 가지더라도, 만약 ε-Greedy한 정책이라면 한번의 업데이트로 Q값이 매우 크게 달라질 위험이 있다.
이를 "Maximization Bias of Q Learning"이라고 한다. - Moving Target
Value를 업데이트하는 식
Q(s,a)← Q(s,a) + µ*( r+ γ*max_aQ(s`, a`) - Q(s,a) )
에서, 일반적으로 함수근사를 사용하지 않는 Tabular Setting에서는 s,a 한쌍에 대해서 Value Function을 업데이트한다고해서 다른 s,a 쌍의 가치값에 영향이 가지는 않는다.
하지만, Q(s,a)자체가 Neural Network라면 이야기가 달라진다.
하나의 s,a쌍에 대해 Q Network를 업데이트 시키면, 다른 s,a쌍에대한 Q Network출력값이 달라지기 때문에 문제가 생기는데, 이를 "Moving Target Issue"라고 한다.
◆ DQN에서는 이를 어떻게 해결했나?
앞서 언급한 두가지 문제점을
DQN에서는 아래와같은 아이디어를 통해 극복했다.
1. Experience Replay
Consecutive Samples (시간적으로 연속된 Sample)의 Strong Correlation으로인한 Q Value의 Maximization bais 문제를 해결하기위해,
DQN에서는 Experience Replay를 도입하여 문제를 해결한다.
D = {s,a,r,s`}이라는 Sample에 대해 여러개의 D를 Replay Buffer라는 장치에 FIFO (First-In-First-Out)큐 방식으로 넣고
학습시 Replay Buffer안에있는 Sample들중 Batch Size만큼 Random으로 Sample을 추출하여 Q Network를 업데이트 하는 것이다.

Experience Replay는 업데이트 이전의 Sample을 사용하므로,
On-Policy계열 알고리즘에는 적용할 수 없고 오직 Off-Policy계열 알고리즘에만 적용이 가능하다는 한계점을 가진다.
2. Moving Target Issue
앞서, Neural Network를 통해 가치함수를 업데이트 시킬때 발생하는 문제인 Moving Target Issue를
DQN에서는 별도의 Target Network를 하나더 둠으로서 이문제를 해결하였다.

Target Network는 C번의 업데이트 이후에 원래의 Q Network의 Weight를 그대로 복사해서 가지고있으며,
Target Network의 출력값을 통해 아래의 Q Update식 중,
Q(s,a)← Q(s,a) + µ*( r+ γ*max_aQ(s`, a`) - Q(s,a) )
Target 값인 r+ γ*max_aQ(s`, a`)를 설정하고 Q(s,a) 네트워크를 업데이트한다.
C번의 횟수동안은 Target값을 고정해둠으로서, Moving Target Issue를 최소화 할 수 있게되는 것이다.
DQN에서 핵심이 되는 개념인 Experience Replay 와 Target Network를 통해 트레이닝하는 과정을 그림으로 표현하면 아래와 같다.

◆ 과거의 상태를 활용하는 MDP
DQN 논문에서 언급되지는 않았으나, 한가지 더 DQN 논문에서 다뤄질 수 있는 개념한가지는
바로 '과거의 상태에 활용'이다.
이는 많은 RL 알고리즘에서 성능을 높이기위한 트릭으로 사용되고 있는데
이것이 왜 트릭이냐면,
때때로 실제의 많은 현실문제에서는 상태 St가 Markovian, 즉, 과거의 상태에대한 정보를 담고있지않은 경우가 많기 때문이다.

DQN에서도, 하나의 State에대한 정의를 위와같은 그림을 통해서 진행하는데,
우선 3x210x160의 input을 Gray Scale로 한개의 Channel로 Down Sample하여
1x210x160으로 만들고, 이를 resize 하여1x84x84크기로 만든 이후에 이를 시간순서대로 4장을 쌓아서 하나의 Observation, 즉 State를 정의한다. (헷갈리면 안되는게, Replay Buffer에서 Random Sampling하는것은 이렇게 4 Frame의 시간순서대로 쌓인 샘플각각에 대해 Randomly Sampling한다는 뜻.)
과거의 정보를 사용해서 새로운 상태를 정의하는 것은 실제로 잘 알려진 Non-MDP 문제를 MDP문제로 바꾸는 기법이다.
[PDF] AI, OR and Control Theory: A Rosetta Stone for Stochastic Optimization | Semantic Scholar
This article attempts to bridge communities by describing how to translate notational systems, while contrasting modeling and algorithmic strategies, and develops some common notational principles that will help to foster communication across communities.
www.semanticscholar.org
◆ Pseudo Code

◆ Soft & Hard Update
앞서 Moving Target 문제에 대해, C 번의 Update마다 Weight를 업데이트함으로서 이를 완화한다고 언급했는데,
이렇게 하면 어느정도는 보정될 수 있으나, 결국 C 번의 Update 마다 Moving Target Issue를 겪게될 수 밖에없다.
이러한 문제점을 완화하기위해 'Soft'하게 Weight를 업데이트하는 방식이 DDPG 논문부터 제안되었는데,
https://arxiv.org/abs/1509.02971
Continuous control with deep reinforcement learning
We adapt the ideas underlying the success of Deep Q-Learning to the continuous action domain. We present an actor-critic, model-free algorithm based on the deterministic policy gradient that can operate over continuous action spaces. Using the same learnin
arxiv.org
내용은 간단하다.
Target Network의 Neural Network의 Weight θ를 업데이트할때, 기존에 저장되어있던 θ를 이용하여 'Soft'하게 업데이트 해주는 것이다.
새로운 Weight를 θ`라고 하면,
아래와같이 수식을 정의할 수 있다.
θ`← 𝜏*θ + (1-𝜏)*θ`
만약 𝜏 = 0인 경우, 그대로 새로운 θ`값을 복사하는 것이고 이는 DQN에서의 방식과 같다.
이를 "Hard Update"라고 한다.
그리고 𝜏가 1에 가까울 수록, 기존에 저장되어있던 Weight θ를 더많이 활용하므로, 더 부드러운 Update를 진행할 수 있다.
이를 "Soft Update"라고 한다.
◆ DQN 성능평가
Nature지에 나온 DQN논문 "Human-level Control through Deep Reinforcement Learning"에는 DQN에대한 성능지표를 표로 명확하게 제시하고 있다.

대다수의 atari게임에서 압도적인 성능을 보였음을 확인할 수 있다.
◆ With / Without Experience Replay & Target Network

가장 Naive한 버전의 DQN은 Experience Replay와 Target Network를 도입하지 않은 버전의 DQN이라 할 수 있는데,
Naive 버전의 DQN보다 Experience Replay와 Target Network가 도입된 DQN이 훨씬더 높은 성능을 보임을 알 수 있다.
그리고 한가지더 확인할 수 있는건,
Breakout게임의 경우 거의 100배 가까이 Naive 한 버전과 Experience Replay와 Target Network가 모두 도입된 버전의 DQN의 성능차이가 발생하는 반면,
River Raid, Space Invader같은 게임에서는 그렇게까지 심한 성능차이를 보이지 않는다는 것을 확인할 수 있다.
이는 게임에 따라 Experience Replay와 Target Network의 효용성이 다르다는 것을 나타낸다.
또한, 이때 제시된 성능지표에서 최소한의 Training Sampling 기준은 10 million 의 Sampling, 즉 10 million Frame이 필요하다고 논문에 나와있는데, 이는 DQN은 많은 RL 알고리즘이 고질적으로 앓고있는 Low Data-Efficiency를 극복하지 못한 것을 의미한다.
(현대에와서는 많은 Feature Representation기법들이 연구되고 개발되면서 이러한 문제들에대해 많은 개선이 진행된 상태이다.)